
Prototypage d’une solution avec OpenAI Platform,
par Magnétic (1/2)
Première partie
Dans cet article, je vais vous parler d'un projet top secret (bon, un peu moins désormais, mais ça ira) que nous avons développé pour un de nos clients historiques. Il s'agit d'un projet qui nous a sorti de nos habitudes de développement et de notre dynamique de gestion habituelle, mais surtout qui nous a permis d'expérimenter. Et ça, c'est souvent quelque chose d'appréciable dans nos métiers. C'est un sujet pour lequel nous avons utilisé le désormais fameux service en ligne OpenAI platform !
Définition : OpenAI est une entreprise spécialisée dans l'intelligence artificielle qui a développé et mis à disposition du public et des entreprises trois outils majeurs : ChatGPT, un module de conversation, Dall•E, qui est un générateur d'images, et enfin l'API OpenAI platform, qui est un service en ligne pour envoyer des requêtes à OpenAI. Le point fort des services d'OpenAI, c'est qu'ils sont tous basés sur l'analyse de langage naturel. Ce sont des IA dites "génératives" : qui produisent des contenus après avoir analysé des instructions écrites.
Également, je tiens à préciser pour les connaisseurs d'OpenAI et de ChatGPT que ce billet a été tapé intégralement avec mes doigts d'humains sur le clavier de mon ordinateur.
Pourquoi Magnétic a utilisé OpenAI ?
L'objectif était le suivant : l'entreprise de notre client possède une base de données d'articles. Celle-ci est alimentée par des contributeurs qui rédigent les contenus des articles. Or, il y a un besoin essentiel pour leur business que les textes des articles publiés soient toujours à jour et pertinents. Ce qui implique de vérifier de grandes quantités de textes à la main (enfin, à l’œil, mais vous aviez compris) et ce travail peut être très vite rébarbatif. Ce contexte, c'est notre problématique initiale.
Vu que les saisies se font depuis une interface web (le client possède son propre CMS Drupal), il semblait logique de vouloir venir y connecter une aide en ligne. Le besoin étant d'automatiser une remontée d'alertes de contenus obsolètes.
Nous avions déjà les informations sur les dates d'édition, celles-ci nous permettent de facilement calculer si un article n'a pas été édité depuis longtemps. Nous pouvions également utiliser les catégories des articles, pour pré-organiser les recherches. Jusque là, pas besoin d’intelligence artificielle : un moteur de recherche performant couplé à un algorithme de traitement peut faire le gros du travail.
Toutefois, l’intérêt principal se trouve dans les textes en eux-mêmes. Peut-on retrouver directement des éléments de langage qui nous permettraient d'extraire un contexte, voire même d'identifier une logique qui nous permettrait d'en tirer des règles.
Par exemple, c'est un peu ce que vous feriez à la lecture d'une page de journal ; vous arriveriez à placer son contenu dans une époque, voire un lieu, et vous n'avez pas besoin de connaître l'intégralité de l'histoire mondiale pour comprendre le sujet de l'article.
Concrètement, Il faut que notre programme puisse accomplir ce qu’un humain ferait avec une lecture rapide.
Et vous l'avez peut-être déjà compris, nous avons utilisé l'API d'OpenAI plateform pour solutionner ce besoin.
L'IA, le machine-learning, c'est quoi ?
Avant d'entamer la suite, je vais devoir faire un peu de théorie, mais ne vous inquiétez pas, je vais tâcher de rester simple. Les connaisseurs pourront largement nuancer ce que je vais expliquer ci-dessous, voire même sauter ce passage.
Le machine-learning, ou apprentissage automatique, est un domaine de l'intelligence artificielle. Son objectif est de faire apprendre et d'améliorer automatiquement les machines à partir de données (du texte, des images, etc).
Je vous l'explique ci-dessous par un exemple.
Un exercice très commun cité dans les manuels destinés aux apprentis data-scientists et futurs ingénieurs en machine-learning est le suivant : comment identifier un e-mail qui est un spam ? L'objectif sera d'obtenir un modèle : c'est à dire un algorithme ou une structure qui est entrainée avec des données, et dont l'intérêt réside dans sa réutilisation, mais aussi son amélioration.
Pour cet exercice, on prendra une grande liste d'e-mails annotés comme sains ou bien comme spams. Un peu comme une machine avec un grand entonnoir, on pousse toutes nos données traitées dans notre modèle (oui, je prends un grand raccourci) qui va devoir trouver "pourquoi" ceux marqués comme spams le sont par rapport aux autres. Et dans notre exemple, on tombera sur des mots qui ressortent bien plus souvent parmi les e-mails annotés comme spams : "publicité", "offre", "cliquez-ici", "promo", etc. Plus un mot est récurent, plus il a de chance d'être identifié.
Et au final, on obtient un modèle qui reconnait le champs lexical des spams dans nos e-mails.
Là où le machine-learning va plus loin que la simple détection, c'est qu'il permet aussi d'identifier des corrélations qui n'auraient pas étés détectées manuellement par un être humain.
L'évolution de notre choix, de Google à OpenAI
Revenons à nos moutons (électriques). Au début du projet, nous avions mené une réflexion sur le développement de notre propre modèle de machine-learning, et ce en utilisant les services du cloud de Google, avec l'aide de leur puissance de calcul. Google propose pléthore d'outils pour créer, récolter, et analyser des données. Tout le "pipeline" de production est disponible sur leurs services. En réalité, l'idée initiale était de développer une solution taillée sur mesure pour faire de l'analyse de langage naturel (Exemple pour aller plus loin : https://www.ibm.com/fr-fr/topics/natural-language-processing). Mais très vite, nous nous sommes heurtés à un problème assez simple : le manque de données.
En effet, si le besoin du client était très clair, un modèle demande de grosses quantités de données pour être performant. Et encore plus pour faire du deep-learning qui est une méthode d'apprentissage qui utilise d'énorme quantités de données pour créer des réseaux de neurones artificiels.
En savoir plus sur l'apprentissage profond : https://www.journaldunet.fr/web-tech/guide-de-l-intelligence-artificielle/1501333-deep-learning-definition-et-principes-de-l-apprentissage-profond/).
En résumé, plus on fait ingérer de données à notre moulinette, mieux c'est. Et nous n'avions pas assez de textes identifiés comme "obsolètes" à notre disposition. Eh bien oui, même si nous avions une grosse centaine d'articles, ce n'était pas assez pour élaborer un modèle suffisamment performant.
Certes, les services Google Cloud proposent eux-aussi des modèles tout-faits à disposition, mais les tests que nous avions menés n'était pas très concluants : les résultats étaient trop flous, pas assez précis. En prime, nous étions dans le cadre d'un prototype plutôt léger, et les outils de Google semblaient disproportionnés au regard de notre besoin.
Et puis, en parallèle de ces expérimentations, je lis un article sur les performances d'OpenAI. Vu que nous étions encore aux prémices de notre premier prototype, je me suis dit "pourquoi ne pas tester avec nos avancées ?".
Après validation avec l'équipe, je créé un compte avec des crédits de requête à consommer, je lis la documentation, qui est plutôt concise, et enfin, j'ouvre leur interface de test. Et là, bam, c'est la claque ! Ça fonctionne très bien ! Pour ceux qui ne connaissent pas déjà, l'interface du service ressemble à ceci :
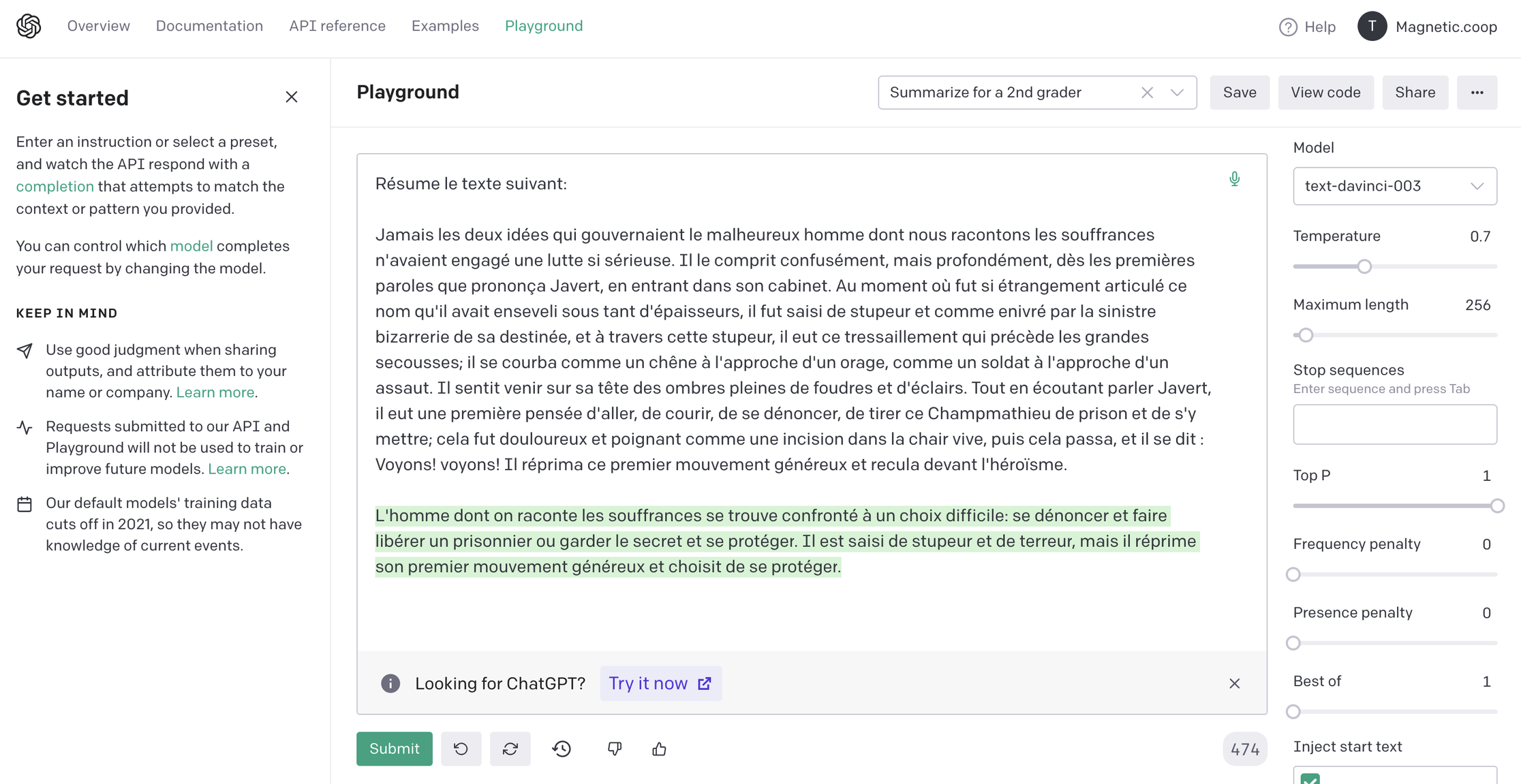
Le principe d'OpenAI est simple et facile d'accès, surtout pour les personnes qui ne développent pas : on soumet un contenu écrit, on ajuste quelques paramètres, et hop, du texte est généré. Il y pas mal d'options, et la possibilité d'utiliser leur API. Même si certaines générations sont à côté de la plaque, voire même hors-sujet, les capacités de détection et de générations sont très abouties. Forcément, je suis un peu dégouté, car le service est tellement facile d'accès que mes expérimentations précédentes me paraissent caduques. Tout ce que l'on a réalisé avant avec Google, OpenAI le fait bien mieux.
Non seulement les modèles pré-entraînés sont performants, mais en plus, il est multilingue et possède un sens aigu de l'analyse sémantique (https://blog.smart-tribune.com/fr/analyse-semantique-definition-enjeux). On peut soumettre des textes plutôt longs, et les sorties sont régulièrement correctes.
Et c'est tout pour cette première partie ! Dans la seconde moitié de cet article, nous allons aborder quelques nuances et réserves sur l'IA et l'intégration du service. Certaines problématiques, notamment éthiques, sont venues à notre esprit pendant la réalisation du projet. Nous pensons que les API d'OpenAI Platform se sont très bien prêtées à notre prototype, mais nous désirons éviter les biais de confirmation, surtout quand certaines solutions peuvent être résolues sans l'intelligence artificielle.
Poursuivre la lecture de l'article (seconde partie)
Thomas Joiris - Web Développeur chez Magnétic
Crédits photo : https://unsplash.com/
Légende photo : CSIR Mk 1, un des cinq premiers ordinateurs au monde.